|
I'm a Ph.D. student at University of Technology Sydney (UTS), affiliated with ReLER Lab, Australian Artificial Intelligence Institute (AAII,), advised by Prof. Yi Yang. I got my B.Eng from Monash University in 2021. |

|
News |
|
My research interests lie in the intersection of computer vision and human visual reasoning. I began my early graduate studies by enhancing generalization capabilities of deep models for scene understanding tasks such as image/video segmentation. Then I applied cutting-edge techniques, such as diffusion models and LLMs, to advance research in high-level scene understanding tasks such and Video Scene Graph Generation. Recently, with the insight that 3D Scene Graph Generation and 3D Scene Generation are highly correlated, I have been pursuing research in hierarchical scene-layout modeling for navigation robotics. I am also exploring LLM-driven multi-agent systems with applications in computer vision and social simulation. Feel free to contact me about any questions. |

|
Mu Chen Ph.D. Thesis, University of Technology Sydney, 2025 UTS OPUS |
|
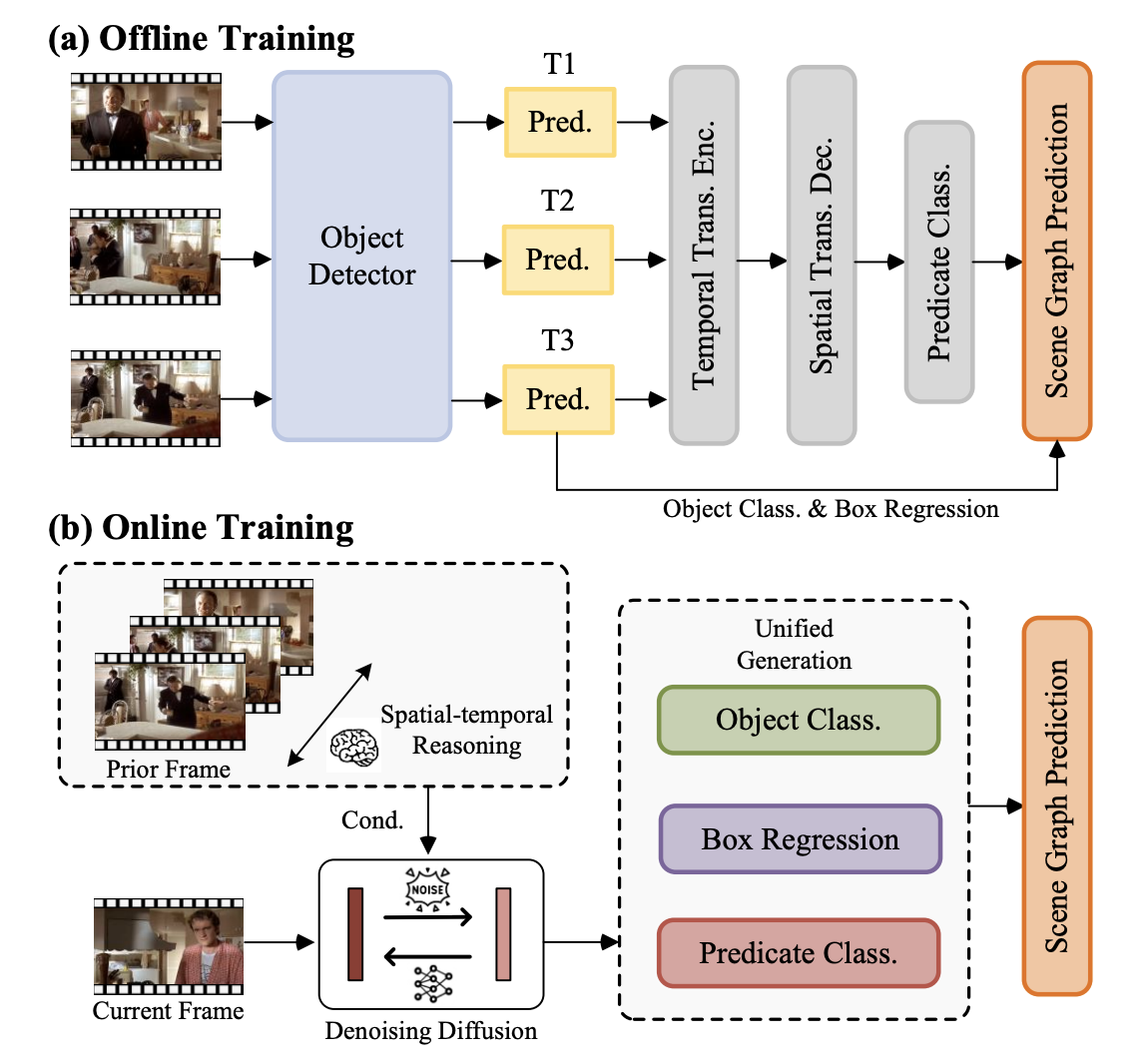
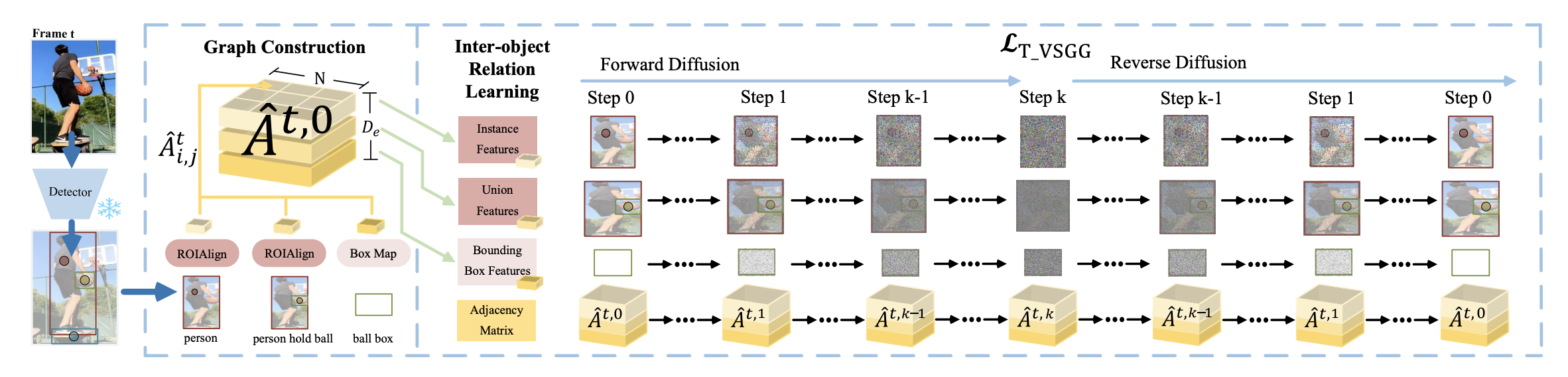
Mu Chen, Liulei Li, Wenguan Wang †, Yi Yang CVPR, 2025 arXiv / code Drawing inspiration from Latent Diffusion Models (LDMs) which generate images via denoising a latent feature embedding, we unify the decoding of object classification, bounding box regression, and graph generation tasks using one shared feature embedding. Then, given an embedding containing unified features of object pairs, we conduct a step-wise Denoising on it within LDMs, so as to deliver a clean embedding which clearly indicates the relationships between objects. |
|
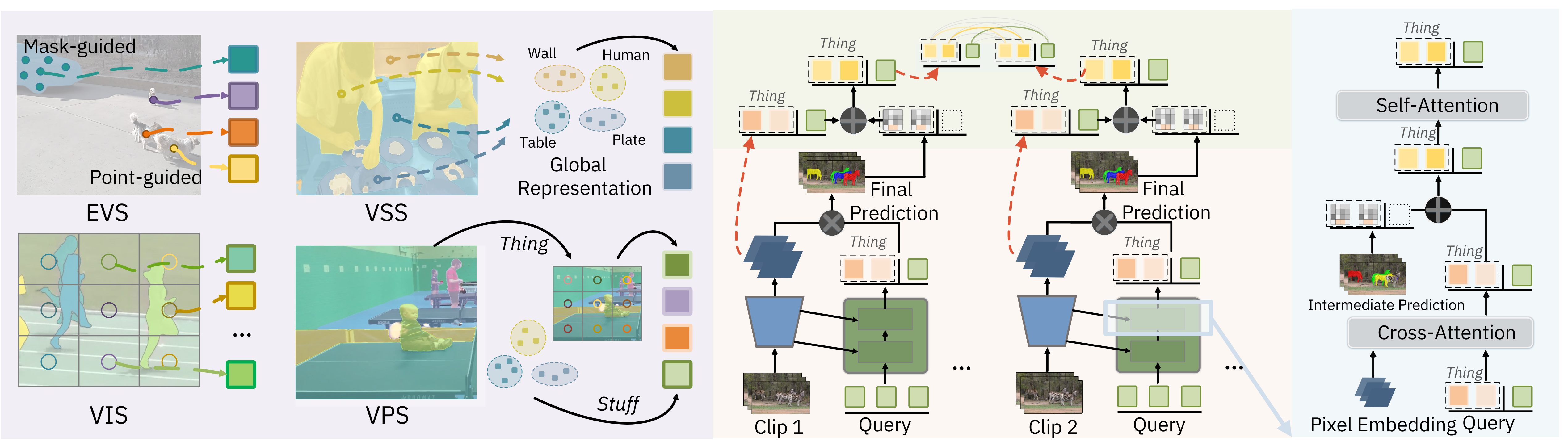
Mu Chen, Liulei Li, Wenguan Wang, Ruijie Quan, Yi Yang † ECCV, 2024 arXiv / code / video (AI TIME) Existing general video segmentation frameworks often suffer from excessive uniformity, overlooking task-specific differences and limiting performance. To address this, we propose GvSeg, which disentangles segmentation targets from appearance, position, and shape, and redesigns query initialization, matching, and sampling strategies for task adaptability. Experiments on seven benchmarks show that GvSeg significantly outperforms prior specialized and general methods across EVS, VIS, VSS, and VPS. |

|
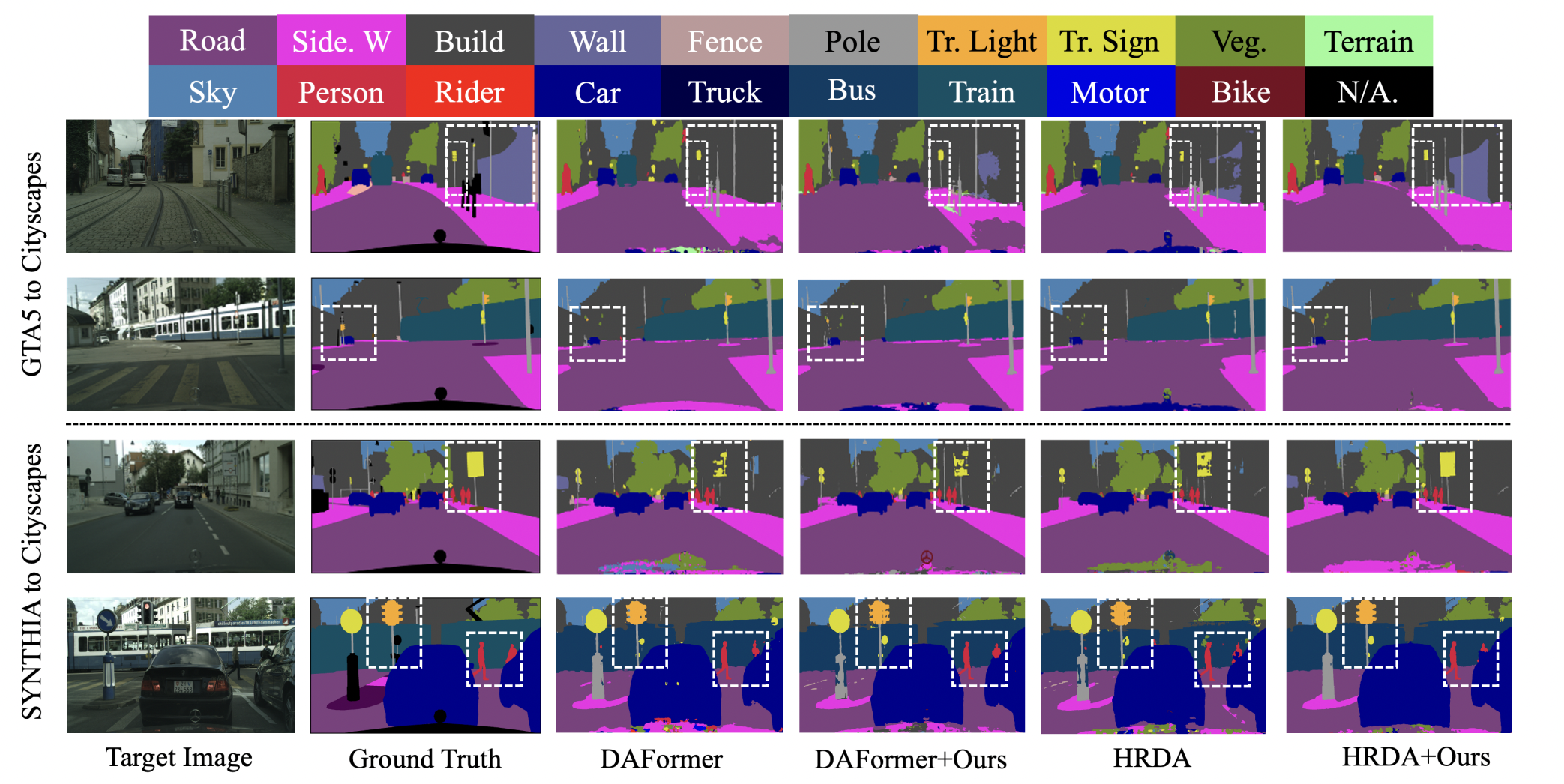
Mu Chen, Zhedong Zheng, Yi Yang † ACM Multimedia, 2024 (Oral Presentation, 3.97% Accept Rate) arXiv / code / video (极市) We observe that semantic categories, such as sidewalks, buildings, and sky, display relatively consistent depth distributions, and could be clearly distinguished in a depth map. Based on such observation, we propose a depth-aware framework to explicitly leverage depth estimation to mix the categories and facilitate the two complementary tasks, i.e., segmentation and depth learning in an end-to-end manner. |

|
Mu Chen, Zhedong Zheng, Yi Yang, Tat-seng Chua † ACM Multimedia, 2023 arXiv / video (AI 新青年) / code We propose a unified pixel- and patch-wise self-supervised learning framework, called PiPa, for domain adaptive semantic segmentation that facilitates intra-image pixel-wise correlations and patch-wise semantic consistency against different contexts. |

|
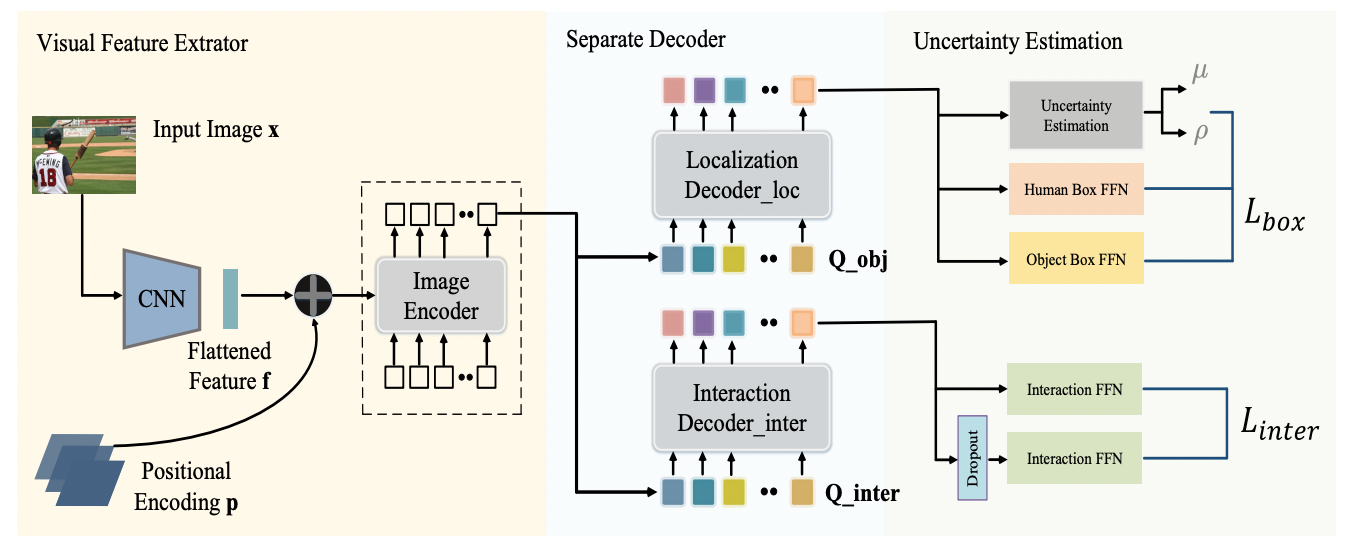
Mu Chen, Minghan Chen, Yi Yang † Computer Vision and Image Understanding (CVIU), 2024 arXiv We propose a novel approach UAHOI, Uncertainty-aware Robust Human-Object Interaction Learning that explicitly estimates prediction uncertainty during the training process to refine both detection and interaction predictions. |

|
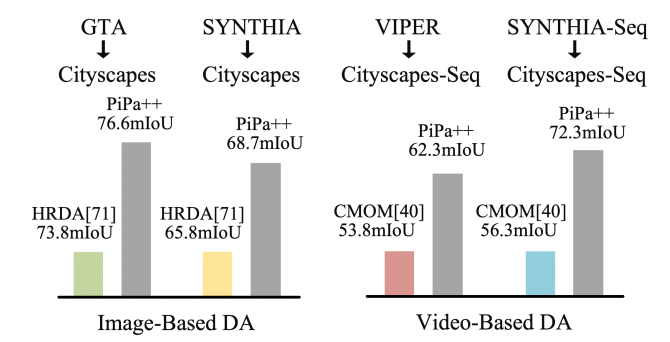
Mu Chen, Zhedong Zheng †, Yi Yang under IJCV review, 2025 arXiv / code An extension version of PiPa towards Video domain. |
|
|
|
|
|
Code stolen from Jon Barron 0v0. |